

Fake News Detection Using Machine Learning
In today’s digital world, many people rely on social media platforms like Facebook, Twitter, and Instagram to stay updated with the news. While it’s quick, easy, and often free to access news online, this convenience also comes with a major problem fake news. Fake news refers to news stories that are completely false or misleading, created intentionally to confuse people or influence their opinions. These stories often spread faster on social media than real news, especially during important events like elections. The rise of fake news can seriously damage public trust and make it harder for people to tell what’s true and what’s not. It can also be used to manipulate political views or spread harmful propaganda.
To help fight this growing problem, researchers are using machine learning and artificial intelligence (AI) to automatically detect fake news. Machine learning models like Naive Bayes, Random Forest, and Logistic Regression can analyze news articles and classify them as real or fake based on patterns in the data. These models learn from large datasets of labeled news stories and are able to make predictions with impressive accuracy sometimes reaching over 70%. In this blog post, we’ll explore how machine learning can be used to detect fake news, walk through a practical example.
Key Characteristics of Fake News
To better understand how fake news works, it’s important to recognize some common signs. Fake news articles often have these features
- Poor Grammar and Spelling: Many fake news stories contain grammatical errors and awkward sentence structures.
- Emotional Language: They are written in a way that triggers strong emotions like anger, fear, or excitement.
- Opinion Manipulation: The content often tries to influence the reader’s opinion on sensitive topics such as politics or health.
- False or Misleading Information: The facts presented are not always true or are taken out of context.
- Clickbait Headlines: These articles use catchy, shocking, or exaggerated headlines to grab attention and get more clicks.
- Too Good (or Bad) to Be True: The news may sound unbelievable or overly dramatic, which is a red flag.
- Unreliable Sources: The source of the information is usually not trustworthy, or no sources are cited at all.
Building a Fake News Detector
PROCEDURE USED FOR FAKE NEWS DETECTION
TOOLS AND LIBRARIES USED
- Python (Programming Language)
- Pandas (For handling datasets)
- Scikit-learn (For machine learning)
- TfidfVectorizer (To convert text to numbers)
- LogisticRegression (For training the model)
STEP 01: DATA COLLECTION AND ANALYSIS
The first step in building a Fake News Detection System is collecting and analyzing the data to understand what kind of news content we are dealing with. For this project, we use the “Fake and Real News Dataset” from Kaggle, which comes in two separate CSV files: Fake.csv (containing fake news articles) and True.csv (containing real news articles).
import pandas as pd
# Load the datasets
fake = pd.read_csv("Fake.csv")
true = pd.read_csv("True.csv")STEP 2: DATA PREPROCESSING
Before training the models, the data must be cleaned and preprocessed. This involves removing unwanted characters, converting text to lowercase, eliminating stop words, and transforming the text into numerical features that machine learning models can understand.
In this project, we use TfidfVectorizer to convert the news text into numerical format by calculating the Term Frequency-Inverse Document Frequency (TF-IDF). This helps us give weight to important words and reduce the influence of common, less meaningful words. We also split the data into training and testing sets to evaluate model performance later.
Inverse Document Frequency: A word is not of much use if it is present in all the documents. Certain terms like a, a, the, on, of etc. appear many times in a document but are of little importance. IDF weighs down the importance of these terms and increase the importance of rare ones. The more the value of IDF, the more unique is the word
# Add labels to the data
fake['label'] = 0
true['label'] = 1
# Combine both datasets
data = pd.concat([fake, true])
data = data.sample(frac=1).reset_index(drop=True)
# Clean the text
import re
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))
def clean_text(text):
text = text.lower() # Lowercase
text = re.sub(r'\W', ' ', text) # Remove special chars
text = re.sub(r'\s+', ' ', text) # Remove extra spaces
text = ' '.join(word for word in text.split() if word not in stop_words) # Remove stopwords
return text
data['cleaned_text'] = data['text'].apply(clean_text)
# Convert text to numbers using TF-IDF
vectorizer = TfidfVectorizer(max_df=0.7)
X = vectorizer.fit_transform(data['cleaned_text'])
y = data['label']STEP 3: MODEL TRAINING
In this step, we train the machine learning model to classify news articles as real or fake.
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LogisticRegression()
model.fit(X_train, y_train)STEP 4. EVALUATE AND USE THE MODEL
Once the model is trained, the next step is to evaluate its performance on unseen test data. This helps us understand how well the model can generalize to new, real-world examples.
We start by predicting the labels for the test dataset
y_pred = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
def predict_news(text):
cleaned = clean_text(text)
vec = vectorizer.transform([cleaned])
result = model.predict(vec)
return "Real News" if result[0] == 1 else "Fake News"This gives us a basic idea of the model’s accuracy — the percentage of correct predictions.
However, accuracy alone isn’t always sufficient, especially in classification problems like fake news detection, where class imbalance (more real news than fake, or vice versa) might be an issue. That’s why we also use other evaluation metrics derived from the confusion matrix, which tells us how many predictions fall into each category
- True Positive (TP): Fake news correctly classified as fake.
- True Negative (TN): Real news correctly classified as real.
- False Positive (FP): Fake news incorrectly classified as real.
- False Negative (FN): Real news incorrectly classified as fake.
This matrix helps us visualize where the model is making mistakes and what types of errors are most common — such as misclassifying fake news as real or vice versa.
You can generate the confusion matrix and classification report like this
# Confusion matrix
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title("Confusion Matrix")
plt.show()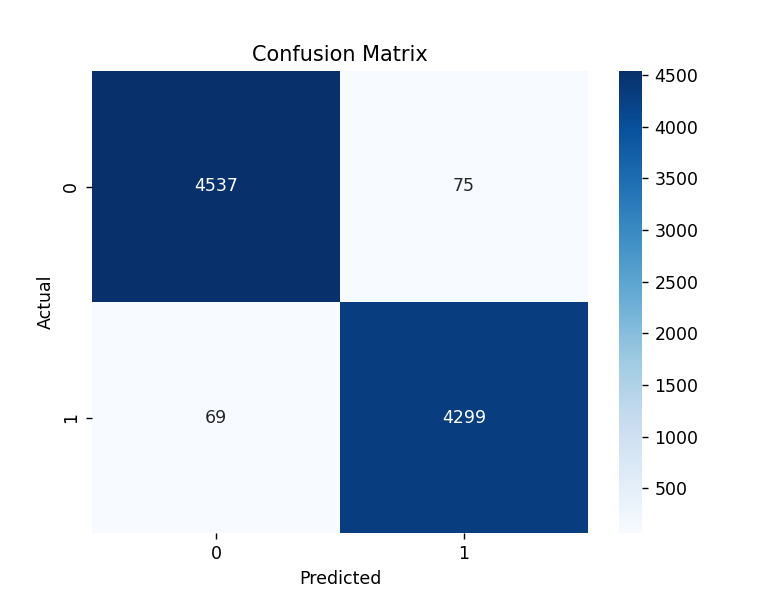
Conclusion
With the increasing spread of misinformation, the need for automated fake news detection systems is more important than ever. Using machine learning and natural language processing, we can effectively classify news articles as real or fake by training models like Logistic Regression on labeled datasets. With the use of this system, we can assist fact-checkers, journalists, and even social media platforms to flag suspicious content, reduce the spread of fake news, and promote truthful information online.